In a recent post I recalled Claude Levy-Strauss’ observation “In Paris, intellectuals need a new toy every 15 years”, and gave a couple of links showing that the most recent IHES-toy has been spreading to other Parisian intellectual circles in recent years.
At the time (late sixties), Levy-Strauss was criticising the ongoing Foucault-hype. It appears that, since then, the frequency of a hype cycle is getting substantially shorter.
To me, this seems like a sensible decision, moving away from (too?) general topos theory towards explicit examples having potential applications to arithmetic geometry.
On the relation between condensed sets and toposes, here’s Dustin Clausen talking about “Toposes generated by compact projectives, and the example of condensed sets”, at the “Toposes online” conference, organised by Alain Connes, Olivia Caramello and Laurent Lafforgue in 2021.
Two days ago, Clausen gave another interesting (inaugural?) talk at the IHES on “A Conjectural Reciprocity Law for Realizations of Motives”.
In the topology of dreams we looked at Sibony’s idea to view dream-interpretations as sections in a fibered space.
The ‘points’ in the base-space and fibers consisting of chunks of text, perhaps connected by links. The topology and shape of this fibered space is still shrouded in mystery.
Let’s look at a simple approach to turn a large number of texts into a topos, and define a loose metric on it.
or to watch her Categories for AI talk: ‘Category Theory Inspired by LLMs’:
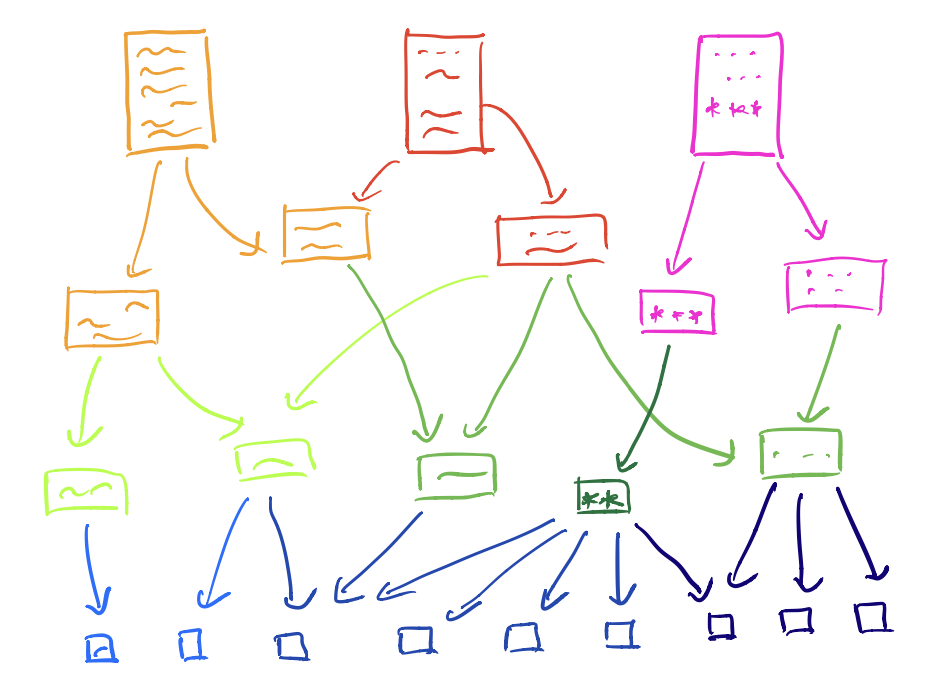
Let’s start with a collection of notes. In the paper, they consider all possible texts written in some language, but it may be a set of webpages to train a language model, or a set of recollections by someone.
Next, shred these notes into chunks of text, and point one of these to all the texts obtained by deleting some words at the start and/or end of it. For example, the note ‘a red rose’ will point to ‘a red’, ‘red rose’, ‘a’, ‘red’ and ‘rose’ (but not to ‘a rose’).
You may call this a category, to me it is just as a poset $(\mathcal{L},\leq)$. The maximal elements are the individual words, the minimal elements are the notes, or websites, we started from.
A down-set $A$ of this poset $(\mathcal{L},\leq)$ is a subset of $\mathcal{L}$ closed under taking smaller elements, that is, if $a \in A$ and $b \leq a$, then $b \in A$.
The intersection of two down-sets is again a down-set (or empty), and the union of down-sets is again a downset. That is, down-sets define a topology on our collection of text-snippets, or if you want, on language-fragments.
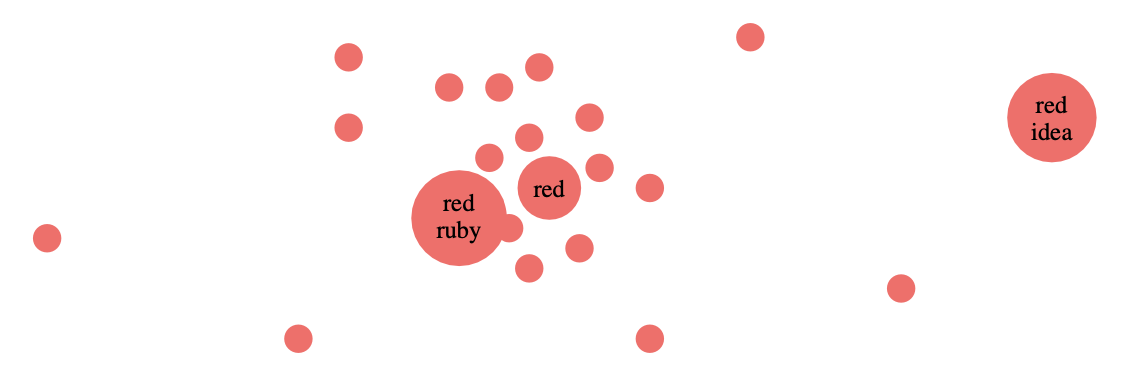
For example, the open determined by the word ‘red’ is the collection of all text-fragments containing this word.
The corresponding presheaf topos $\widehat{\mathcal{L}}$ is then just the category of all (set-valued) presheaves on this topological space.
As an example, the Yoneda-presheaf $\mathcal{Y}(p)$ of a text-snippet $p$ is the contra-variant functor
$$(\mathcal{L},\leq) \rightarrow \mathbf{Sets}$$
sending any $q \leq p$ to the unique map $\ast$ from $q$ to $p$, and if $q \not\leq p$ then we map it to $\emptyset$. If $A$ is a down-set (an open of over topological space) then the sections of $\mathcal{Y}(p)$ over $A$ are $\{ \ast \}$ if for all $a \in A$ we have $a \leq p$, and $\emptyset$ otherwise.
The presheaf $\mathcal{Y}(p)$ already contains some semantic information about the snippet $p$ as it gives all contexts in which $p$ appears.
Perhaps interesting is that the ‘points’ of the topos $\widehat{\mathcal{L}}$ are the notes we started from.
Recall that Connes and Gauthier-Lafaey want to construct a topos describing someone’s unconscious, and points of that topos should be the connection with that person’s consciousness.
Suppose you want to unravel your unconscious. You start by writing down a large set of notes containing all relevant facts of your life. Then you construct from these notes the above collection of snippets and its corresponding pre-sheaf topos. Clearly, you wrote your notes consciously, but probably the exact phrasing of these notes, or recurrent themes in them, or some text-combinations are ruled by your unconscious.
Ok, it’s not much, but perhaps it’s a germ of an potential approach…
Now we come to the interesting part of the paper, the ‘enrichment’ of this poset.
Surely, some of these text-snippets will occur more frequently than others. For example, in your starting notes the snippet ‘red rose’ may appear ten time more than the snippet ‘red dwarf’, but this is not visible in the poset-structure. So how can we bring in this extra information?
If we have two text-snippets $p$ and $q$ and $q \leq p$, that is, $p$ is a connected sub-string of $q$. We can compute the conditional probability $\pi(q|p)$ which tells us how likely it is that if we spot an occurrence of $p$ in our starting notes, it is part of the larger sentence $q$. These numbers can be easily computed and from the rules of probability we get that for snippets $r \leq q \leq p$ we have that
$$\pi(r|p) = \pi(r|q) \times \pi(q|r)$$
so these numbers (all between $0$ and $1$) behave multiplicative along paths in the poset.
Nice in theory, but it requires an awful lot of computation. From the paper:
The reader might think of these probabilities $\pi(q|p)$ as being most well defined when $q$ is a short extension of $p$. While one may be skeptical about assigning a probability distribution on the set of all possible texts, it’s reasonable to say there is a nonzero probability that cat food will follow I am going to the store to buy a can of and, practically speaking, that probability can be estimated.
Indeed, existing LLMs successfully learn these conditional probabilities $\pi(q|p)$ using standard machine learning tools trained on large corpora of texts, which may be viewed as providing a wealth of samples drawn from these conditional probability distributions.
It may be easier to have an estimate $\mu(q|p)$ of this conditional probability for immediate successors (that is, if $q$ is obtained from $p$ by adding one word at the beginning or end of it), and then extend this measure to all arrows in the poset by taking the maximum of products along paths. In this way we have for all $r \leq q \leq p$ that
$$\mu(r|p) \geq \mu(r|q) \times \mu(q|p)$$
The upshot is that this measure $\mu$ turns our poset (or category) $(\mathcal{L},\leq)$ into a category ‘enriched’ over the unit interval $[ 0,1 ]$ (suitably made into a monoidal category).
I’ll spare you the details, just want to flash out the corresponding notion of ‘enriched presheaves’ which are the objects of the semantic category $\widehat{\mathcal{L}}^s$ in the paper, which is the enriched version of the presheaf category $\widehat{\mathcal{L}}$.
An enriched presheaf is a function (not functor)
$$F~:~\mathcal{L} \rightarrow [0,1]$$
satisfying the condition that for all text-snippets $r,q \in \mathcal{L}$ we have that
Note that the enriched (or semantic) Yoneda presheaf $\mathcal{Y}^s(p)(q) = \mu(q|p)$ satisfies this condition, and now this data not only records the contexts in which $p$ appears, but also measures how likely it is for $p$ to appear in a certain context.
Another cute application of the condition on the measure $\mu$ is that it allows us to define a ‘distance function’ (satisfying the triangle inequality) on all text-snippets in $\mathcal{L}$ by
So, the higher $\mu(q|p)$ the closer $q$ lies to $p$, and now the snippet $p$ (example ‘red’) not only defines the open set in $\mathcal{L}$ of all texts containing $p$, but now we can structure the snippets in this open set with respect to this ‘distance’.
In this way we can turn any language, or a collection of texts in a given language, into what Lawvere called a ‘generalized metric space’.
It looks as if we are progressing slowly in our, probably futile, attempt to understand Alain Connes’ and Patrick Gauthier-Lafaye’s claim that ‘the unconscious is structured like a topos’.
Even if we accept the fact that we can start from a collection of notes, there are a number of changes we need to make to the above approach:
there will be contextual links between these notes
we only want to retain the relevant snippets, not all of them
between these ‘highlights’ there may also be contextual links
texts can be related without having to be concatenations
we need to implement changes when new notes are added
… (much more)
Perhaps, we should try to work on a specific ‘case’, and explore all technical tools that may help us to make progress.
1. The unconscious is structured as a topos (Jacques Lacan argued it was structured as a language), because we need a framework allowing logic without the law of the excluded middle for Lacan’s formulas of sexuation to make some sense at all.
2. This topos may differs from person to person, so we do not all share the same rules of logic (as observed in real life).
3. Consciousness is related to the points of the topos (they are not precise on this, neither in the talk, nor the book).
4. All these individual toposes are ruled by a classifying topos, and they see Lacan’s work as the very first steps towards trying to describe the unconscious by a geometrical theory (though his formulas are not first order).
Surely these are intriguing ideas, if only we would know how to construct the topos of someone’s unconscious.
Let’s go looking for clues.
At the same meeting, there was a talk by Daniel Sibony: “Mathématiques et inconscient”
Sibony started out as mathematician, then turned to psychiatry in the early 70ties. He was acquainted with both Grothendieck and Lacan, and even brought them together once, over lunch, some day in 1973. He makes a one-line appearance in Grothendieck’s Récoltes et Semailles, when G discribes his friends in ‘Survivre et Vivre’:
“Daniel Sibony (who stayed away from this group, while pursuing its evolution out of the corner of a semi-disdainful, smirking eye)”
In his talk, Sibony said he had a similar idea, 50 years before Connes and Gauthier-Lafaye (3.04 into the clip):
“At the same time (early 70ties) I did a seminar in Vincennes, where I was a math professor, on the topology of dreams. At the time I didn’t have categories at my disposal, but I used fibered spaces instead. I showed how we could interpret dreams with a fibered space. This is consistent with the Freudian idea, except that Freud says we should take the list of words from the story of the dream and look for associations. For me, these associations were in the fibers, and these thoughts on fibers and sheaves have always followed me. And now, after 50 years I find this pretty book by Alain Connes and Patrick Gauthier-Lafaye on toposes, and see that my thoughts on dreams as sheaves and fibered spaces are but a special case of theirs.”
This looks interesting. After all, Freud called dream interpretation the ‘royal road’ to the unconscious. “It is the ‘King’s highway’ along which everyone can travel to discover the truth of unconscious processes for themselves.”
“The dream brings blocks of words, of “compacted” meanings, and we question, according to the good old method, each of these blocks, each of these points and which we associate around (we “unblock” around…), we let each point unfold according to the “fiber” which is its own.
I introduced this notion of the dream as fibered space in an article in the review Scilicet in 1972, and in a seminar that I gave at the University of Vincennes in 1973 under the title “Topologie et interpretation des rêves”, to which Jacques Lacan and his close retinue attended throughout the year.
The idea is that the dream is a sheaf, a bundle of fibers, each of which is associated with a “word” of the dream; interpretation makes the fibers appear, and one can pick an element from each, which is of course “displaced” in relation to the word that “produced” the fiber, and these elements are articulated with other elements taken in other fibers, to finally create a message which, once again, does not necessarily say the meaning of the dream because a dream has as many meanings as recipients to whom it is told, but which produces a strong statement, a relevant statement, which can restart the work.”
Key images in the dream (the ‘points’ of the base-space) can stand for entirely different situations in someone’s life (the points in the ‘fiber’ over an image). The therapist’s job is to find a suitable ‘section’ in this ‘sheaf’ to further the theraphy.
It’s a bit like translating a sentence from one language to another. Every word (point of the base-space) can have several possible translations with subtle differences (the points in the fiber over the word). It’s the translator’s job to find the best ‘section’ in this sheaf of possibilities.
This translation-analogy is used by Daniel Sibony in his paper Traduire la passe:
“It therefore operates just like the dream through articulated choices, from one fiber to another, in a bundle of speaking fibers; it articulates them by seeking the optimal section. In fact, the translation takes place between two fiber bundles, each in a language, but in the starting bundle the choice seems fixed by the initial text. However, more or less consciously, the translator “bursts” each word into a larger fiber, he therefore has a bundle of fibers where the given text seems after the fact a singular choice, which will produce another choice in the bundle of the other language.”
This paper also contains a pre-ChatGPT story (we’re in 1998), in which the language model fails because it has far too few alternatives in its fibers:
I felt it during a “humor festival” where I was approached by someone (who seemed to have some humor) and who was a robot. We had a brief conversation, very acceptable, beyond the conventional witticisms and knowing sighs he uttered from time to time to complain about the lack of atmosphere, repeating that after all we are not robots.
I thought at first that it must be a walking walkie-talkie and that in fact I was talking to a guy who was remote control from his cabin. But the object was programmed; the unforeseen effects of meaning were all the more striking. To my question: “Who created you?” he answered with a strange word, a kind of technical god.
I went on to ask him who he thought created me; his answer was immediate: “Oedipus”. (He knew, having questioned me, that I was a psychoanalyst.) The piquancy of his answer pleased me (without Oedipus, at least on a first level, no analyst). These bursts of meaning that we know in children, psychotics, to whom we attribute divinatory gifts — when they only exist, save their skin, questioning us about our being to defend theirs — , these random strokes of meaning shed light on the classic aftermaths where when a tile arrives, we hook it up to other tiles from the past, it ties up the pain by chaining the meaning.
Anyway, the conversation continuing, the robot asked me to psychoanalyse him; I asked him what he was suffering from. His answer was immediate: “Oedipus”.
Disappointing and enlightening: it shows that with each “word” of the interlocutor, the robot makes correspond a signifying constellation, a fiber of elements; choosing a word in each fiber, he then articulates the whole with obvious sequence constraints: a bit of readability and a certain phrasal push that leaves open the game of exchange. And now, in the fiber concerning the “psy” field, chance or constraint had fixed him on the same word, “Oedipus”, which, by repeating itself, closed the scene heavily.
Okay, we have a first potential approximation to Connes and Gauthier-Lafaye’s elusive topos, a sheaf of possible interpretation of base-words in a language.
But, the base-space is still rather discrete, or at best linearly ordered. And also in the fibers, and among the sections, there’s not much of a topology at work.
Perhaps, we should have a look at applications of topology and/or topos theory in large language models?