 A
A
previous post the best LaTeX system was a commercial for Gerben
Wierda’s i-Installer to get a working tetex
distribution. I’ve been working happily with this TeX-system for two
years now but recently run into a few (minor) problems. In the process
of solving these problems I created myself a second tetex-system
more or less by accident. This is what happened. On the computer at the
university I once got fun packages running such as a chess-, go-
and Feynman diagrams-package but somehow I cannot reproduce this
on my home-machine, I get lots of errors with missing fonts etc. As I
really wanted to TeX some chess-diagrams I went surfing for the most
recent version of the chess-package and found one for Linux and
one under the Fink-project : the chess-tex package. So, I did a
sudo fink install chess-tex
forgetting that in good Fink-tradition you can
only install a package by installing at the same time all packages
needed to run it, so I was given a whole list of packages that Fink
wanted to install including a full tetex-system. Did I want to
continue? Well, I had to think on that for a moment but realized that
the iTex-tree was living under /usr/local whereas Fink
creates trees under /sw so there should not really be a problem,
so yes let’s see what happens. It took quite a while (well over an hour
and a half) but when it was done I had a second full TeX-system, but how
could I get it running? Of course I could try to check it via the
command line but then I remembered that there is an alternative
front-end for TeXShop namely iTeXMac
which advertises that it can run either iTeX or the Fink-distribution of
tetex. So I downloaded it, looked in the preferences which indeed
contains a pane
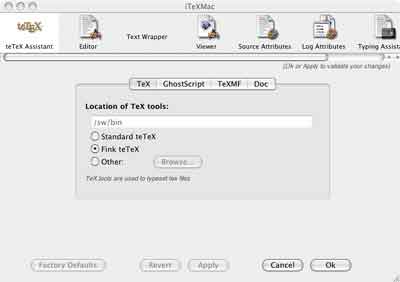
where you can choose between using the standard
tetex-distribution or the Fink-distribution and iTeXMc finds
automatically the relevant folders. So I wrote a quick chess diagram ran
it trough iTeXMac and indeed it produced the graphics I expected! This
little system gave me some confidence in the Fink-distribution so I
fired up the Fink-Commander and looked under categories :
text for other TeX packages I could install and there were plenty :
Latex2HTML, Latex2rtf, Feynman, tex4ht and so on. Installing them with
the commander is fun : just click on the package you want and click
‘Install’ under the Source-dropdown window
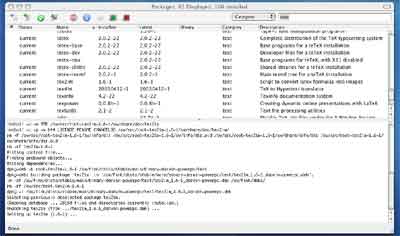
and in the lower part of the window you can follow the
installation process, whereas the upper part tells you what packages are
already installed and what their version-number is. I still have to
figure out how I will add new style files to this fink-tree and I have
to get used to the iTeXMac-editor but so far I like the robustness of
the system and the easy install procedure, so try it out!
 This morning there was an intriguing post on
This morning there was an intriguing post on  Never
Never